agirouter.products
Build and run generative AI applications with accelerated performance, maximum accuracy, and lowest cost at production scale.
Inference that’s fast, simple, and scales as you grow.
FAST
Run leading open-source models like Llama-3 on the fastest inference stack available, up to 4x faster than vLLM. Outperforms Amazon Bedrock, and Azure AI by over 2x.
COST-EFFICIENT
Agirouter Inference is 11x lower cost than GPT-4o when using Llama-3 70B. Our optimizations bring you the best performance at the lowest cost.
scalable
We obsess over system optimization and scaling so you don’t have to. As your application grows, capacity is automatically added to meet your API request volume.
Serverless Endpoints for leading open-source models
Access 100+ models through serverless endpoints – including Llama 3, RedPajama, Falcon and Stable Diffusion XL. Endpoints are OpenAI compatible.
Test models in Chat, Language, Image, and Code Playgrounds.
Access 8 leading embeddings models – including models that outperform OpenAI’s ada-002 and Cohere’s Embed-v3 in MTEB and LoCo Benchmarks.
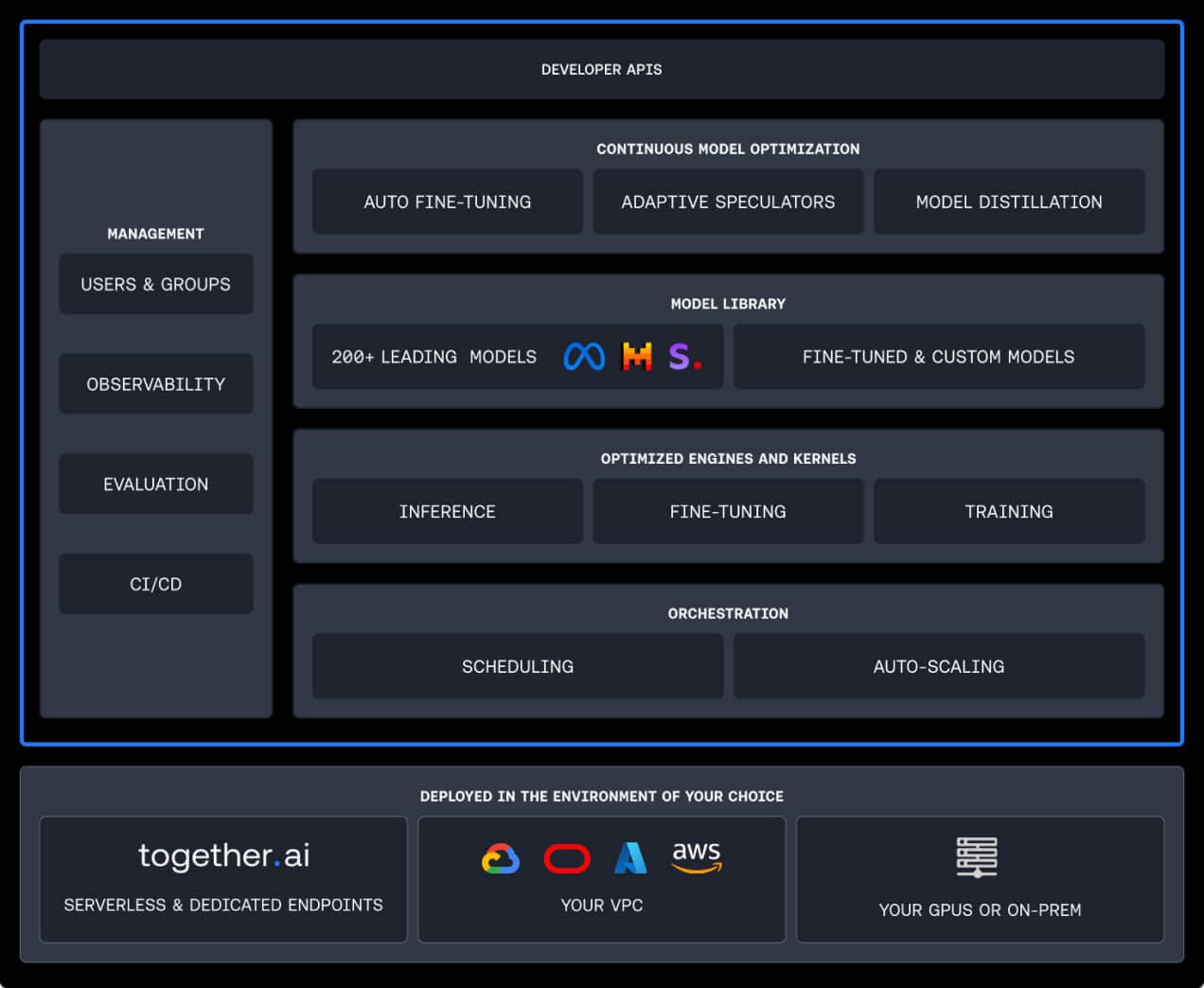
Dedicated Endpoints for any model
Choose any kind of model — open-source, fine-tuned, or even models you’ve trained.
Choose your hardware configuration. Select the number of instances to deploy and how many you’ll auto-scale to.
Tune for fast latency versus high throughput — simply by adjusting the max batch size.

Integrate Agirouter Inference Engine into your application
Integrate models into your production applications using the same easy-to-use inference API for either Serverless Endpoints or Dedicated Instances.
Leverage the Agirouter embeddings endpoint to build your own RAG applications.
Show streaming responses to your end users — almost instantly.
Perfect for enterprises — performance, privacy, and scalability to meet your needs.
Performance
You get faster tokens per second, higher throughput and lower time to first token. And, all these efficiencies mean we can provide you compute at a lower cost.
SPEED RELATIVE TO VLLM
LLAMA-3 8B AT FULL PRECISION
COST RELATIVE TO GPT-4o
The Agirouter Inference Engine sets us apart.
01
FlashAttention 3 and Flash-Decoding
The Agirouter Inference Engine integrates and builds upon kernels from FlashAttention-3 along with proprietary kernels for other operators.
02
Advanced speculative decoding
The Agirouter Inference Engine integrates speculative decoding algorithms such as Medusa and SpecExec. It also comes with custom-built draft models that are more than 10x Chinchilla optimal, to achieve the fastest performance.
03
Quality-preserving quantization
Agirouter AI quantization achieves the highest accuracy and performance. Built on proprietary kernels including MHA and GEMMs that are optimized for LLM inference, tuned for both pre-fill and decoding phases.
Privacy
FAST
Run leading open-source models like Llama-3 on the fastest inference stack available, up to 4x faster than vLLM. Outperforms Amazon Bedrock, and Azure AI by over 2x.
COST-EFFICIENT
Agirouter Inference is 11x lower cost than GPT-4o when using Llama-3 70B. Our optimizations bring you the best performance at the lowest cost.
scalable
We obsess over system optimization and scaling so you don’t have to. As your application grows, capacity is automatically added to meet your API request volume.
Choose from best-in-class open-source models like Llama 3.2 and Qwen2.5, or bring your own model. Our platform supports open-source, proprietary, and custom models for any use cases — text, image, vision, and multi-modal.
Get started with our serverless APIs. We optimize every model to run for the best performance and price.
1import os 2from Agirouter import Agirouter 3 4client = Agirouter() 5 6stream = client.chat.completions.create( 7 model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo", 8 messages=[{"role": "user", "content": "What are some fun things to do in New York?"}], 9 stream=True, 10) 11 12for chunk in stream: 13 print(chunk.choices[0].delta.content or "", end="", flush=True) 14 15# Signup to get your API key here: https://api.agirouter/ 16# Documentation for API usage: https://docs.agirouter/ 17Spin up dedicated endpoints for any model with 99.9% SLAs
Conifgurable auto scaling – as your traffic grows, capacity is automatically added to meet your API request volume.
Choose from 200+ models or bring your own
Achieve greater accuracy for your domain specific tasks.
Support for LoRA fine-tuning
Expert guidance for deployment and optimization
Fine-tune models with your own data
Host your fine-tuned model for inference when it’s ready.
Get started nowAgirouter GPU Clusters
We offer high-end compute clusters for training and fine-tuning. But premium hardware is just the beginning. Our clusters are ready-to-go with the blazing fast Agirouter Training stack. And our world-class team of AI experts is standing by to help you. Agirouter GPU Clusters has a >95% renewal rate. Come build with us, and see what the hubbub is about.
A single platform that continuously optimizes your models
- Drive the best performance, price and accuracy for your models.
- Implement advanced optimization techniques like auto fine-tuning and adaptive speculators to continuously improve model performance over time.
Highly reliable GPU clusters for large-scale inference and foundation model training
- Top spec NVIDIA H100 and H200s available – our GPUs undergo a rigorous acceptance testing process to ensure less failures.
- Deploy with Agirouter Training and Inference engines for 25% faster training, and 75% faster inference than PyTorch
- Our proprietary engines have been built by leading researchers who created innovations like Flash Attention.
Performance metrics
SPEED RELATIVE TO VLLM
LLAMA-3 8B AT FULL PRECISION
COST RELATIVE TO GPT-4o
Benefits
FAST
Run leading open-source models like Llama-3 on the fastest inference stack available, up to 4x faster than vLLM. Outperforms Amazon Bedrock, and Azure AI by over 2x.
COST-EFFICIENT
Agirouter Inference is 11x lower cost than GPT-4o when using Llama-3 70B. Our optimizations bring you the best performance at the lowest cost.
scalable
We obsess over system optimization and scaling so you don’t have to. As your application grows, capacity is automatically added to meet your API request volume.
Hardware specs
A100 PCIe Cluster Node Specs
- - 8x A100 / 80GB / PCIe
- - 200Gb non-blocking Ethernet
- - 120 vCPU Intel Xeon (Ice Lake)
- - 960GB RAM
- - 7.68 TB NVMe storage
A100 SXM Cluster Node Specs
- - 8x NVIDIA A100 80GB SXM4
- - 200 Gbps Ethernet or 1.6 Tbps Infiniband configs available
- - 120 vCPU Intel Xeon (Sapphire Rapids)
- - 960 GB RAM
- - 8 x 960GB NVMe storage
H100 Clusters Node Specs
- - 8x Nvidia H100 / 80GB / SXM5
- - 3.2 Tbps Infiniband network
- - 2x AMD EPYC 9474F 18 Cores 96 Threads 3.6GHz CPUs
- - 1.5TB ECC DDR5 Memory
- - 8x 3.84TB NVMe SSDs
Customers Love Us
“Agirouter GPU Clusters provided a combination of amazing training performance, expert support, and the ability to scale to meet our rapid growth to help us serve our growing community of AI creators.”